Abstract. I taught a neural network how to play the board game Catan using supervised learning through self-play. When training, I utilized both temporal-difference and Monte-Carlo tree search methods, along with a residual neural network structure. The resulting model achieved an intermediate level of play.
Table of Contents
- Introduction
- Catan implementation
- Network architecture
- Training procedure
- Results
- Conclusions
- References
Note. I would like to point out that this experiment is not true reinforcement learning; it is supervised learning. Instead of computing a reward at each stage, we train a neural network to predict the end goal, and we exploit temporal differences to use this result to update network predictions at earlier states.
1. Introduction
Catan is a strategic board game where players attempt to control the resources on the board in order to score points. Throughout the game, players take turns rolling dice, trading resource cards, purchasing development cards, and building roads and settlements, until they reach 10 points. There are many luck-based elements to the game, such as who goes first, the distribution of the dice rolls, and the development card shuffle. Hence, it is often difficult to evaluate a given position, especially when players are pursuing contrasting strategies.
When playing online with friends, I noticed that the AI bots were atypically poor, even at their most difficult setting. Instead of developing long-term strategies, the bots pursued simple ones, such as drawing lots of development cards. The purpose of this project is to train a competitive Catan playing neural network; I hoped that my network would be able to make moves that a professional Catan player would categorize as "strong" or "intelligent".
A notable example of training a neural network through self-play is G. Tesauro's TD-Gammon developed during the 1990s [12]. His networks consisted of less than 5 hidden layers and 100 hidden units—networks that are orders of magnitude smaller than many modern networks. During training, each turn it would predict the win probability for each possible move, and then select the move with the highest overall win probability. His program then backpropagated the game result using a temporal-difference (TD) method, meaning that instead of comparing each individual prediction with the result, they would be compared successively to each other to minimize their differences. This approach showed remarkable success: An initial model achieved a strong intermediate ranking after 200,000 training games, and an enhanced model achieved a level of play only matched by the world's best players after 1,500,000 training games.
Another interesting example of learning through self-play is the work of DeepMind Technologies in the 2010s on Atari video games [7], chess, and Go [9]. They took advantage of greatly increased computer power and new image recognition methods, e.g., modern convolutional neural network architectures. This enabled the creation of a single model capable of playing multiple Atari games, along with a state-of-the-art chess playing bot, and, for the first time, a super-human level Go playing program. When training their networks, they utilized various Monte-Carlo tree search (MCTS) algorithms, which would randomly choose moves (or board positions) that had not been visited many times before.
My approach to Catan directly builds on the research discussed above. I trained a residual neural network to predict whether a given player will finish first, second, or third, using a TD-method combined with a simplified MCTS algorithm. I tested this approach in two settings: (1) with the board tiles and numbers fixed and (2) without the board fixed. In both trials, I disabled player-to-player trading while limiting the number of players to 3; I hope to train a more general model in the future.
In case (1), I created a network that won each game in an average of 73 dice rolls. Other analyses suggest the average number of rolls to win being in the range 60–70—for instance, in [1], they counted an average of 71 rolls in a four person game. Hence, 73 rolls imply my model is a little slow, as a three person game should finish more quickly than a four person game. The slight increase in the number of rolls could be attributed to disabling player-to-player trading. I also found that, by personally playing my model, it was better than an amateur player, but the network still struggled with late game strategy. It seems capable of occasionally winning, albeit not at a high rate. I think this can be fixed by employing MCTS rollouts during the end game.
In case (2), the network was a bit slower, winning each game in an average of 86 dice rolls. In turn, this reduced the model from playing at an intermediate level and challenging for wins to a beginner level. Two possible ways to improve this model are either creating human engineered features for the model to interpret (e.g., how many resources each settlement position borders), or creating a larger model with additional training time. The former seems simpler because the latter would likely require much more computational power than I had available.
2. Catan implementation
I coded my own version of Catan in Python to utilize PyTorch. The code is distributed across five files and available on my GitHub repository:
- player.py contains the player class. This manages for each player their resource and development cards, settlements and cities, etc. Notably, it contains an array of the player's predictions, i.e., the outputs from the network made each move, which is utilized when updating the network's weights.
- board.py compromises of the board class. It is responsible for generating the board positions and development card ordering. It also contains maps corresponding each position to an integer so we can translate board information to the input tensor for our network.
- game.py holds the game class. It handles almost all gameplay. In particular, the game class contains methods which allow our network to interact with the board by generating a tensor containing the board and a player's possible moves, then feeding this tensor to our model in order to choose a move.
- network.py contains the CatanNetwork and ResidualBlock classes. The CatanNetwork is a residual neural network built out of ResidualBlock objects.
- training.py is composed of the training procedure. In it are the network and the optimizer, and it is responsible for updating the network's parameters.
Here is the call graph:
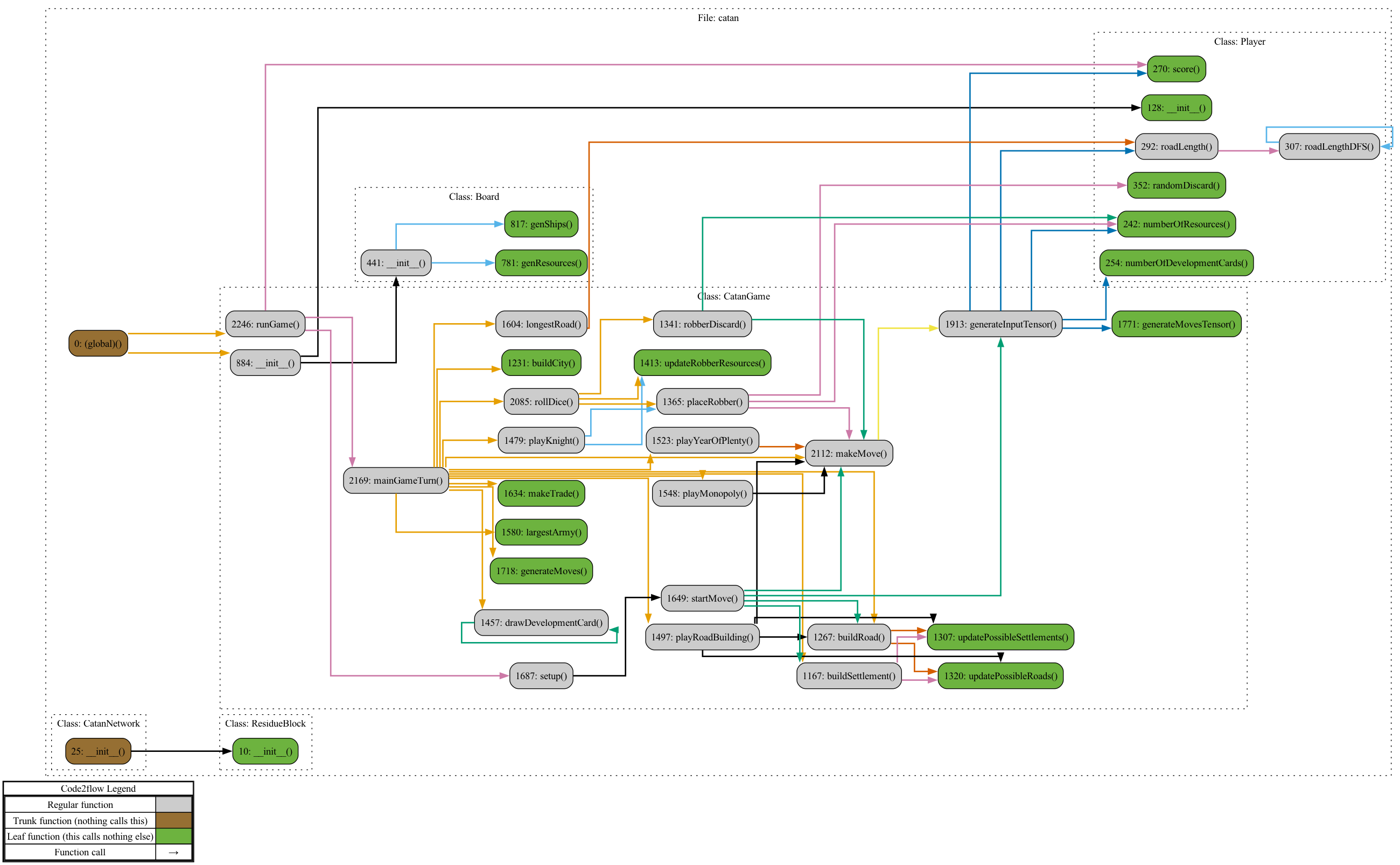
I programmed the board based on the notion of sets containing different vertices. Each corner of a tile is considered a vertex (or settlement position), each road and trading port is defined by two vertices, and each tile is defined by six vertices. This simplified calculations for where a player could build a road or settlement, the length of their longest road, and so on.
Each turn, the game generates an input tensor for the network. This consists of the known board information for the current player along with their possible moves. For each move, I then created a temporary tensor containing the board information and a single 1 in the moves portion indicating this move. Inputting this tensor to the network is philosophically equivalent to asking it "What is the predicted finishing position given this board and this move?". If a MCTS move was not chosen that turn, cf. §4, the program then chose the move with the best given move position.
One thing that helped with training was rotating the input tensor with respect to each player's information, e.g., each player would see their statistics listed first, then the player taking the following turn, and so on. I found it difficult to train the network effectively without this, even if the network was given the current player number.
3. Network architecture
The CatanNetwork is a 10 layer feedforward residual neural network consisting of a fully connected input layer, 4 residual blocks [3], and a fully connected output layer. Specifically, the input layer maps our 1782 input features linearly to 500 neurons. Each residual block performs a 500 $ \times $ 500 linear transformation and ReLU, another 500 $ \times $ 500 linear transformation and ReLU, adds the input (also known as a skip connection), then performs another ReLU. Finally, our output linearly maps our 500 new features to a single output value, which is supposed to correspond to what position the player is expected to finish. In total, the CatanNetwork has 2,896,001 parameters.
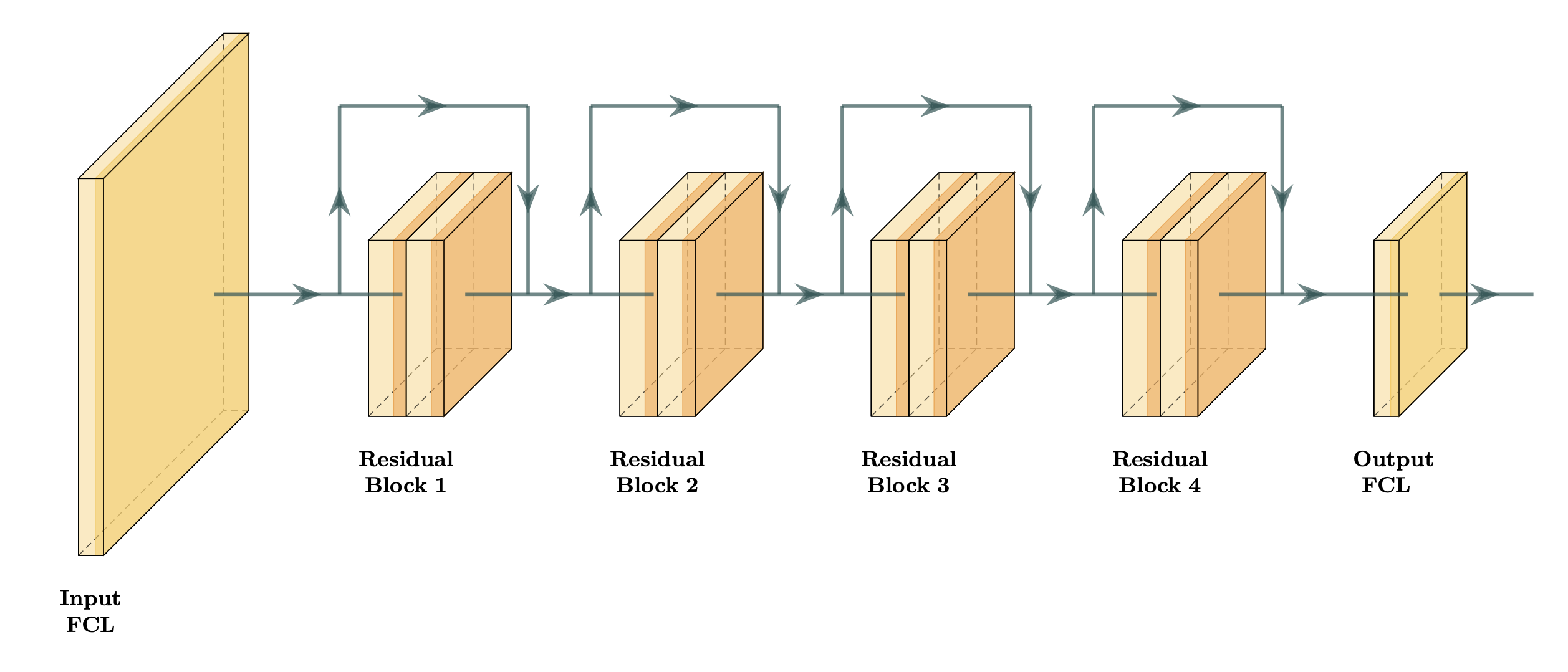
I tested a variety of architectures before settling on the CatanNetwork. I started with some simple models: single layer networks with 50, 100, or 1100 neurons. I found these models to be too unstable and to suffer from catastrophic forgetting. I also tried other naive configurations, such as 5 fully connected layers with 1000 neurons each. These all seemed to lack the quickness to converge and ability not to forget that the CatanNetwork possessed.
One important hyperparameter was the number of neurons in the hidden layers. I chose 500 to create a sufficiently large network while also prioritizing training time. I discuss in §4.4 that, by exploiting weight decay, having too large of a network is more of a concern than too small. I hoped the CatanNetwork would be large enough, although now I believe a bigger model is needed. Thus, with the chosen number of neurons, the network was able to play a game of Catan approximately every 4 seconds, which translates to 22,500 games per day.
I am interested in experimenting with deeper architectures or more hidden neurons in the future. One comparison I made when training my model was to image recognition architectures. If you consider the current board information as an image, where instead of classifying images we are classifying moves, then it is natural to compare the number of parameters. Strong image recognition architectures for the CIFAR-100 data have anywhere from 2,500,000 to 25,000,000 parameters, cf. [2]. This was one justification I made for my choice of architecture.
4. Training procedure
In this section, I describe the ideas that were utilized in training my bot. First, in §4.1, I explain why I utilized temporal-difference methods and how they are implemented in my code. Subsequently, in §4.2, I detail my simplified Monte-Carlo tree search algorithm. Next, in §4.3, I explain my choice of criterion, a smooth L1 loss, and why gradient clipping was necessary. In §4.4, I justify using the AdamW optimizer. Finally, in §4.5, I discuss how adjusting the batch size and learning rate affected training.
4.1. Temporal-differences
Temporal-difference (TD) methods suggest that, instead of computing the loss as the difference between the model predictions and the outcome of the game, we should compute the loss as the differences between successive predictions. In other words, we have the computer check to see if it has indeed gained an advantage. This incentivizes our model to predict outcomes that do not change significantly each turn, forming a "smooth" curve until settling upon the real score of the game. In practice, TD methods are easy to implement while often having drastic effects on model training.
For example, suppose that we compute the loss only using the final game scores. Recall that we would like to predict whether the player will finish in first, second, or third place when playing Catan. Let network A consistently predict that our player is going to finish in third place each turn, whereas network B alternates between predicting first place and third place. If our player finishes in second place, both models would be penalized the same compared to the game outcome: each turn they had an error of 1. However, it makes little sense for model A to keep jumping between places first and third: why not take their average and choose second? Whereas, for model B, it could be that our player luckily gained a place at the end of the game due to the actions of another player, and hence the increase from third to second.
TD methods have shown to be successful in a variety of game playing tasks. One of the first implementations was Samuel's checkers program, where he created a program which could play checkers better than himself [8]. TD methods were abstracted by Sutton in [11], where he defined his TD-lambda; furthermore, he showed that, with certain natural constraints, TD-lambda is capable of modeling arbitrary training sets. Likewise, Tesauro named his program TD-gammon in reference to the importance of TD methods when training it [12].
I exploited TDs as follows. Each turn, the program records the prediction the current player has made for their chosen move; this yields one prediction vector for every player. Once the game has concluded, for each player, I construct a labels vector by copying and then shifting the predictions vector one coordinate over—forgetting the first prediction made—and inserting the final game score in the final position. Effectively, this compares subsequent predictions to each other, and the final prediction to the final game score. Finally, I compute the loss, cf. §4.3, and backpropagate it.
Another possible algorithm would be updating the weights of the network every time a player made a move; this seemed impractical for two reasons. The first is that it would increase training time for what appeared to be little gain: without knowing the outcome of the game, the network cannot validate its predictions. The second reason is that my network currently compares subsequent predictions made by each player; this could not be done each turn for each player, as it would interfere with computing the loss of other predictions. In other words, the network weights would change between predictions, which will throw an error in PyTorch. To combat this problem, I would have had to have the network output a vector of final place predictions, one for each player. Then we could compare subsequent vectors without needing to wait to return to the same player.
4.2. Monte-Carlo tree search
Monte-Carlo tree search (MCTS) methods are based on the idea of infrequently having a model choose random moves, testing the accuracy of the model's predictions for otherwise ignored moves. In other words, according to some distribution, the model will randomly choose a move, then play out the rest of the game as normal. This move could be chosen on the first turn or the last. Ideally, this prevents the model from getting stuck in a non-optimal local minimum.
One previous implementation of MCTS was by the researchers at Deepmind when developing AlphaGo [2]. Their method was based on treating the game of Go like a search tree, where they would store the action value (i.e., how strong the move is), visit count, and prior probability for each move (e.g., "leaf"). This allowed the model to visit infrequently made moves with higher probability, followed by a playout in order to collect a sample action value. However, since in Catan the board is randomly chosen, the idea of designing a search tree relative to board position seemed ineffective. The sample space is patently too large. One could try to program a MCTS algorithm which considers how often each individual move occurs, regardless of the board position, but I decided upon something simpler.
I constructed a naiver version of MCTS: I gave each move a 1/1000 chance of being chosen randomly, and if a move was in fact selected, then the rest of the game was played out without a random move. Note that I deleted previous predictions before this move, as they were no longer relevant to the current game; it may be better to keep them and simply forget the turn in which the random move was made. I decided upon this probability as it provided an approximate 30% chance that a setup move would be picked, i.e., one of the initial settlements or roads; it also yields a good distribution of middle to late game random moves, in practice.
A downside to my MCTS algorithm is that it causes random spikes in error when training. This is because when the network enters an explored region of the sample space, its final prediction can be drastically wrong. Furthermore, there are fewer sample points to average over before computing the error, exacerbating this problem. To combat this issue, I exploited a variety of methods that I will explain in further detail later: decreasing the learning rate, increasing the batch size, using a Huber loss, and gradient clipping.
4.3. Criterion and gradient clipping
I employed a smooth L1 loss, also known as a Huber loss, when training the CatanNetwork. For each sample point, this loss function is quadratic when the loss is between 0 and 1 while being linear when the loss is greater than 1. The main purpose of employing this loss is to prevent a highly inaccurate final prediction from overtly affecting the network, meaning if the player places 1st but the network mistakenly outputs 6th, then the loss will only be 4.5 instead of 12.5.
Likewise, I exploited gradient clipping to prevent any drastically wrong predictions from hurting the model. This scales down the gradients to be at most $ L^2 $ norm 0.1, which I chose after examining how different gradient norms affected training. Due to the MCTS algorithm, the network would occasionally experience a very large loss—e.g., 40x the usual loss—and a consequently increased gradient. Without gradient clipping, this would effectively untrain the model, causing all progress to be lost.
One seemingly contradictory thing that I experienced when training was that a higher loss often meant the network played better. This is because the largest contributor to the loss, due to the TD method and exaggerated by the MCTS algorithm, is the difference between the final prediction and the actual game score. Thus, the fewer number of turns means the more this final prediction matters, causing the loss to go up when the network is playing better. I could have modified the loss function by normalizing it with respect to game length, and this is something I am considering testing in the future, althought any attempted implementation led to volatility.
4.4. AdamW
Adam, short for adaptive moment estimation, was introduced by D. Kingma and J. Ba in [5]. Unlike, for example, stochastic gradient descent with momentum, Adam uses computationally efficient estimations of the first and second moments in order to compute an adaptive learning rate. This acts as a form of automatic annealing, allowing it to often converge quicker than, for example, SGD, which requires the user to manually adjust the step size. Mathematically, Kingma and Ba proved that Adam has an average $ O(\sqrt{T}) $ online regret bound for convex optimization, meaning it indeed converges if the loss functions are convex. Practically, they showed that Adam converged quicker on image recognition tasks than many other optimizers. Adam has been popular in training large language models, cf. [4]
AdamW is a modified version of Adam that utilizes weight-decay to prevent unbounded network parameter growth. I. Loshchilov and F. Hutter proved in [6] that, unlike for SGD, $ L^2 $-regularization and weight-decay are not equivalent for Adam. Hence, they introduced a version of Adam which uses decoupled weight decay called AdamW. They showed that it performed better than Adam on image recognition tasks during later stages of training, i.e., after 1000 epochs, while both lagged behind SGD. This is in stark comparison to Kingma and Ba's experiments, which only tested their optimizer over 200 epochs. This is important for my Catan model, as the number of epochs will reach more than 100,000.
For these reasons, I utilized AdamW when training my model. I set the initial learning rate to 5e-5, then I decreased it by a multiple of 5 each time the model stopped learning. The rest of the AdamW learning parameters, $ \beta_1, \beta_2, \epsilon $, etc., I left to be the default values as given by Loschilov and Hutter in [6].
4.5. Batch size and learning rate
Increasing the batch size and decreasing the learning rate, on the surface, have similar effects when training a model: each slows down learning while decreasing the volatility of the learning steps. This has been particularly shown to be true in the case of image recognition, cf. [10]. I used both techniques. I began training with a batch size of 1 game and a learning rate of 5e-5. When training stagnated, I decreased the learning rate to 1e-5 or doubled the batch size. I only decreased the learning rate once; meanwhile, I found doubling the batch size from 1 to 2 and then from 2 to 4 caused improvements in performance each time. This could be because AdamW has an adaptive learning rate, which likely caused further decreases to not yield significant gains.
5. Results
This section is split into two parts. First, in §5.1, I detail training a network which only models a fixed board position. Next, in §5.2, I describe training a more general network which does not require the board to be fixed. Note that the average number of turns to win reported during training are slightly higher than my estimation, as MCTS is enabled, adding randomness to the network's gameplay. All training was done on an Intel i9-13900K processor (24 cores), because training on a GPU would have been slower due to the lack of parallelism in my code.
5.1 A fixed board network
My first model was trained by fixing the board, i.e., the resources, roll numbers, and ships were all fixed. I found this network to train well and achieve an intermediate level of play. The training procedure was as follows: I started with a learning rate of 5e-5 for 38,000 epochs, which I decreased to 1e-5 until epoch 53,000; finally, I increased the batch size to 2 for the remainder of the training. The network was trained for a total of 117,750 epochs.
As discussed in §4.3, the model's error is partially inversely correlated with the number of turns taken to win the game. This was seemingly one of the major drawbacks of using TDs: during the late stages of training, the model would struggle to optimize error, as attempts to do so could end up increasing it. The later drops in error can be attributed to increasing the batch size, which in turn averages out the spikes that can occur due to my MCTS algorithm.
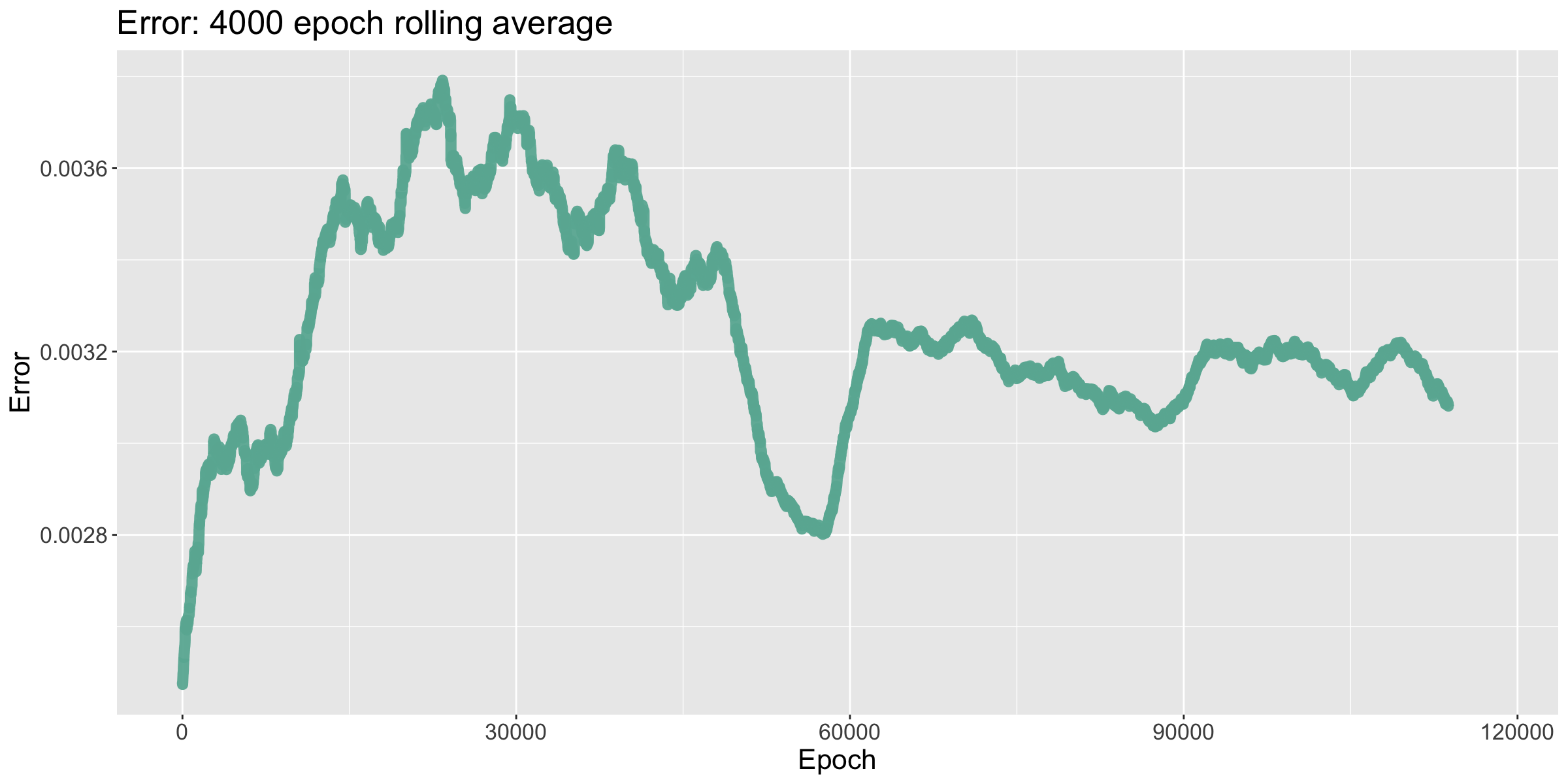
The number of turns the model took to win each game quickly decreased until it flatlined, winning each game in around 85 turns. I then decreased the learning rate, which brought it down to winning in around 77 turns. Lastly, when I doubled the batch size, the number of tursn to win started to drop, but then shot back up. Watching the network improve and then forget during the fine tuning stage of training suggests that a larger model is needed.
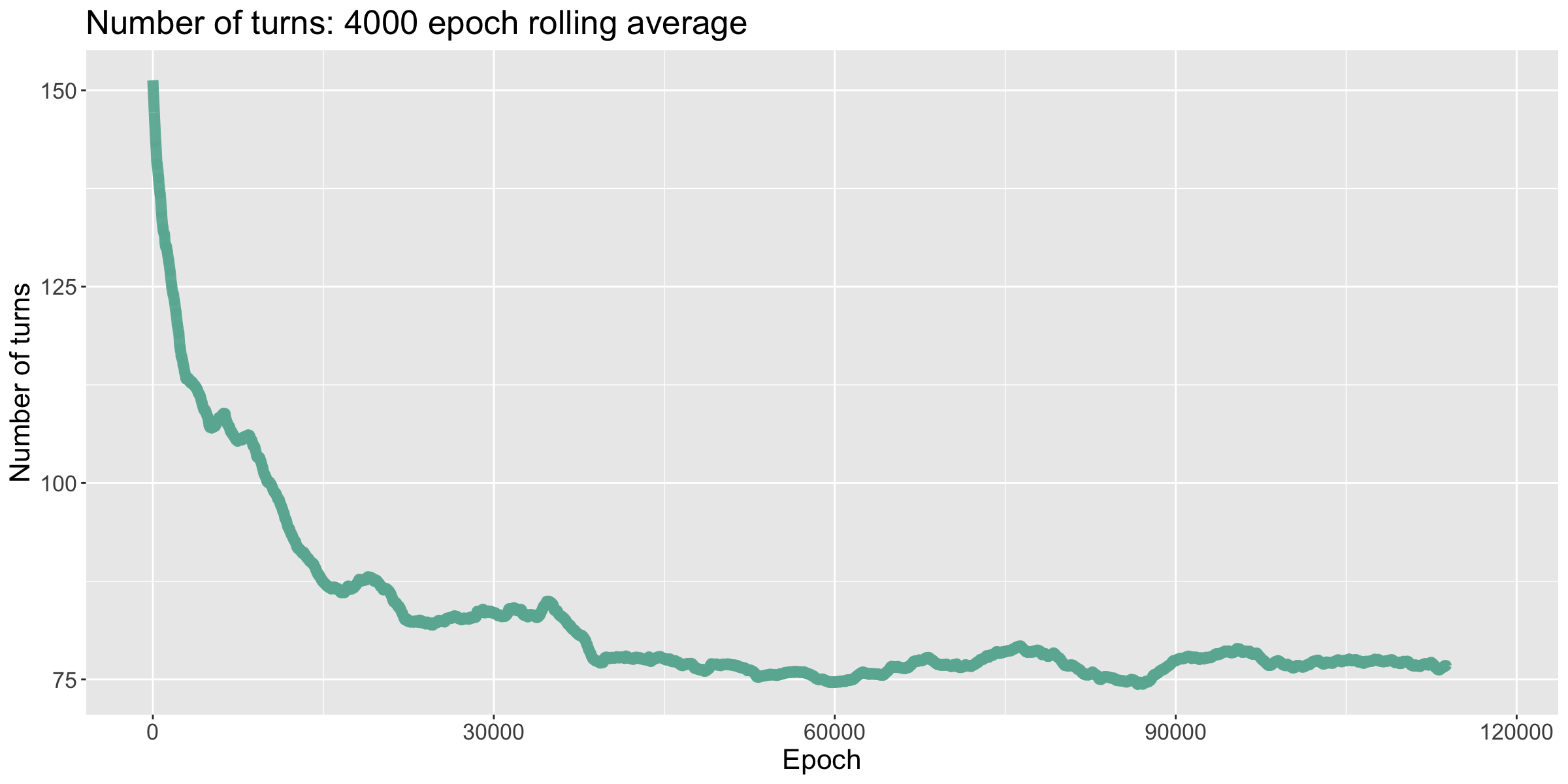
When I played against this model, I noticed that it excelled at early game strategy. Its initial settlement placements were strong and took me by surprise. During the middle game, I was on my toes—the model kept pace with me, and I struggled to outscore it. However, during the end game the model began to seriously struggle. When I built settlements in positions where it wanted to settle, it would build a road to that settlement, then realize it could not settle there. The network likewise had a difficult time capitalizing on new resources: while I was able to take advantage of all the resources I was receiving, quickly building settlements and cities, it seemingly stagnated. The final scores were 10, 8, and 7.
5.2 A general network
My second model was trained on arbitrary board positions, i.e., the resources, roll numbers, and ships were all shuffled each game. This network struggled to play at a high level, which I simply attribute to not having enough training data and parameters to model the task at hand. I believe a general model could be created with more computational power. The training procedure was as follows: I started with a learning rate of 5e-5 for the first 48,000 epochs, when I decreased the learning rate to 1e-5; next, at epoch 63,000, I doubled the batch size to 2; and finally, at epoch 95,000, I again doubled the batch size to 4. The network was trained for a total of 102,300 epochs.
The error of the model again grew proportionally to the number of turns taken to win the game. The volatility of the error early on compared to its relative stability later is a consequence of increasing the batch size.
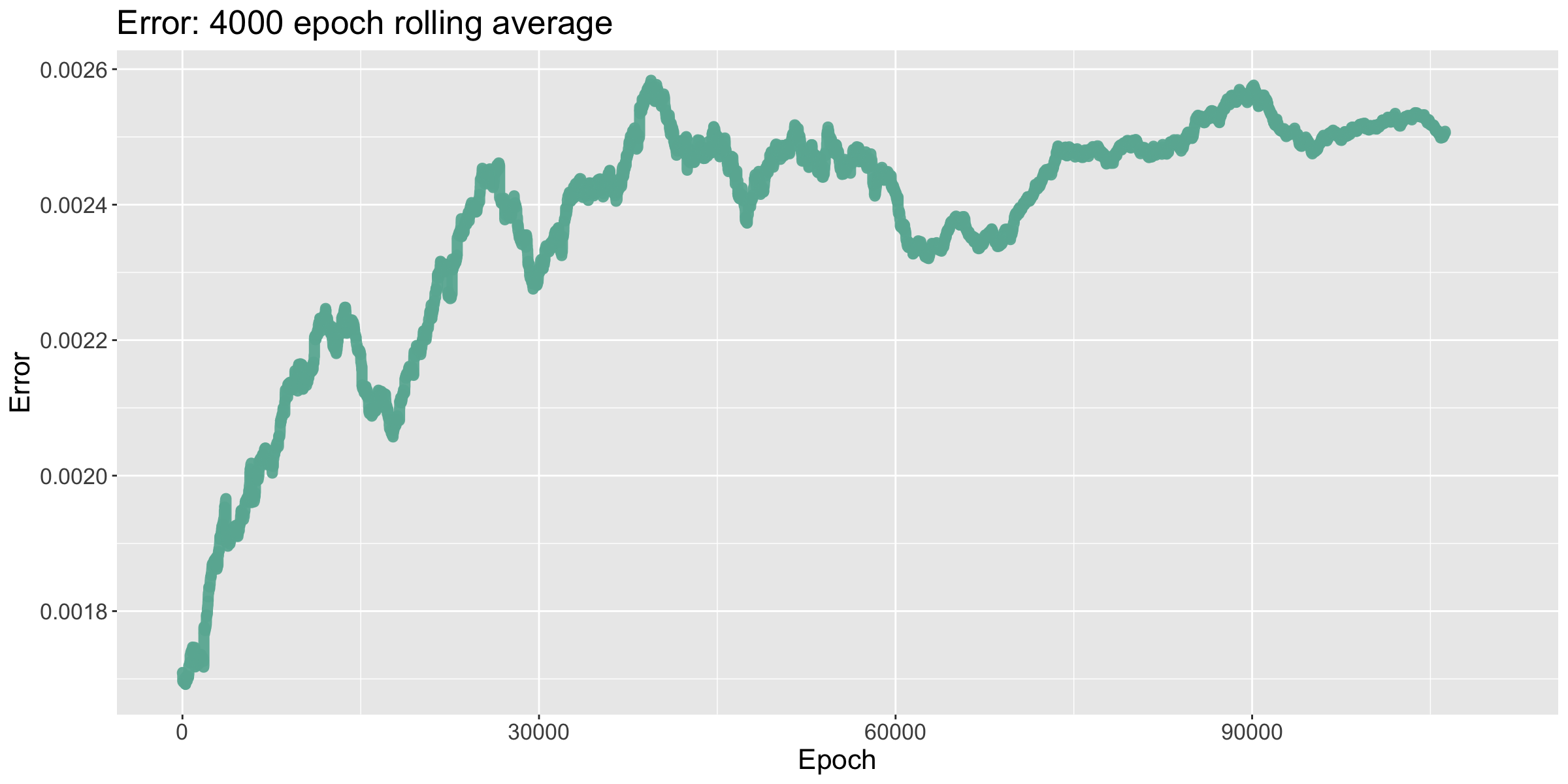
This time, the number of turns taken to win decreased until it flatlined at around 112 turns. I decreased the learning rate, bringing it to win in ~104 turns. I then increased the batch size to 2 games, causing it to win in ~91 turns; and finally, the batch size was increased to 4 games, causing it to win in ~89 turns.
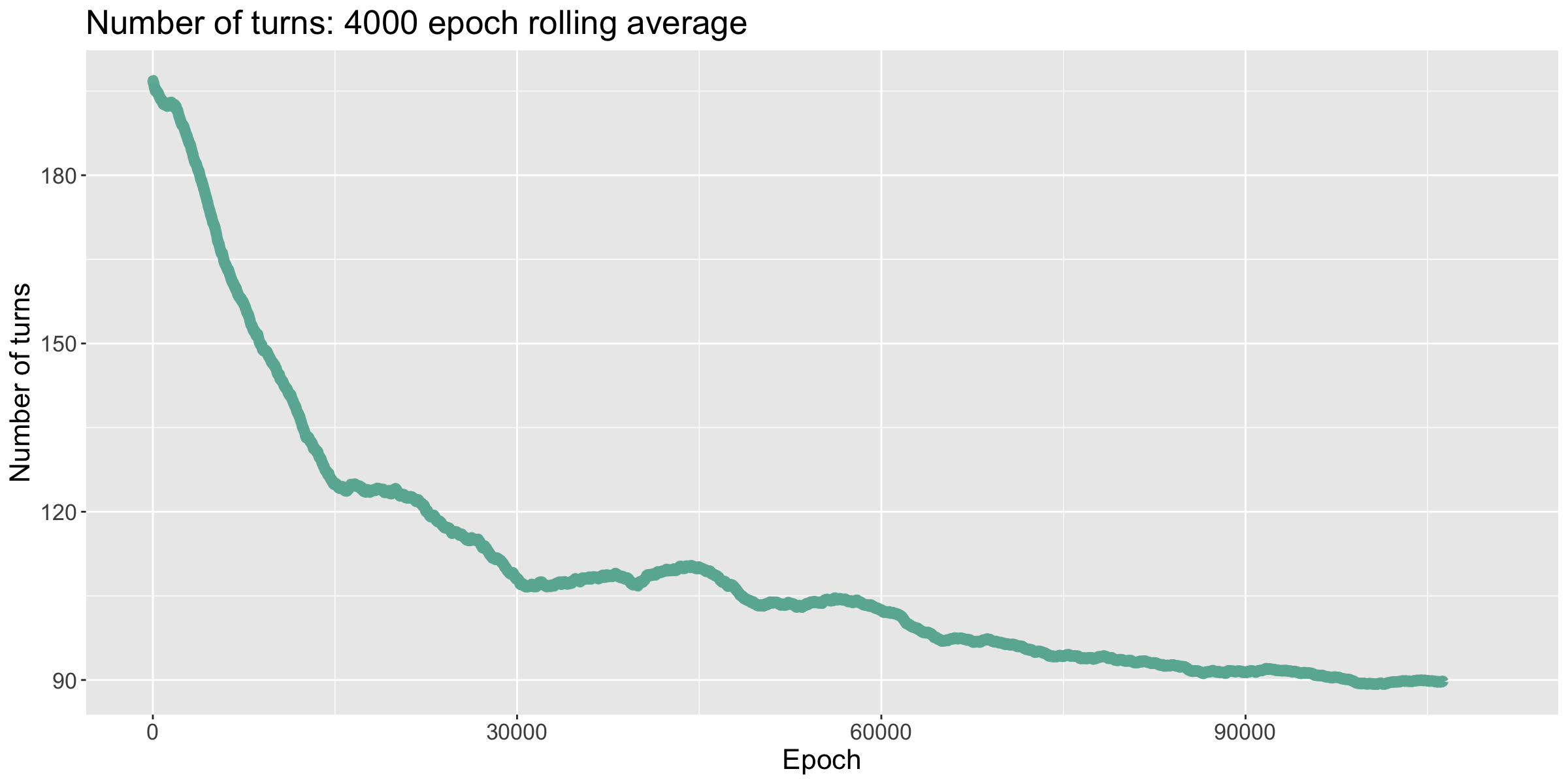
It becomes apparent why this model struggles so much when compared to the fixed board model. The fixed board model already had a difficult time playing against me when I settled in places it had not seen before. Now, the inherent level of randomness the model was seeing likely made any major pattern detection difficult. I was hoping for the opposite effect: by playing many contrasting board positions, the model would have the chance to better understand and adapt to my own settlement strategies. Perhaps this is just a case where further training is necessary.
This also demonstrates a specific area where our algorithm might struggle. While it is extremely good at fixed board positions, as it can treat the game like a search tree (e.g. chess openings), randomizing the board very much complicates this search. The question then becomes "How can we make this shuffled board not appear…shuffled?" One idea that I had was to add additional input features, such as the total number of resources bordering each settlement location. This could eliminate the possibility for the sublime moves that my fixed board model was making, or it could simply guide the model to making better decisions.
6. Conclusions
My models act as a proof of concept, demonstrating that Catan can be played at a high-level using supervised learning. My training procedure should be compared to that of DeepMind's models for Atari, chess, and Go. Their models are often trained on large GPU (or TPU) clusters, which was not feasible here. For instance, their chess bot, AlphaZero, was trained in 2017 using approximately 5,000 TPUs in parallel. As a rough estimate, suppose they trained for 9 hours—the amount of time it took them to beat Stockfish 8—then divide by a factor of 8 to take into account advances in GPU efficiency. This gives us 5625 hours of compute or ~234 days, compared to just training for a week like I did. It also aids significantly in performing experiments, thus resolving certain issues I had with training my model. Thus, I am led to believe that if provided with ample compute, we could achieve similar results here.
Likewise, one significant problem I noticed is how slow each MCTS playout was, especially each forward pass through the network. For example, I wanted to implement a version of my model which could train itself on (or at least study) the current board position while playing a human. However, this was seemingly impossible without (a) further computational power or (b) a faster implementation. I pursued the latter: I programmed a version of my bot in C++ using LibTorch. This cut the MCTS playout time almost in half, but this is simply not enough. An interesting approach here could be using a smaller model which is quickly on the CPU trained while playing.
Some possible future improvements are the following:
- Provide the network with past moves and dice rolls.
- Fix the problem from TDs that error can become inversely correlated to the number of turns to win.
- Utilize attention mechanisms to keep track of cards for trading.
- Enable AMSGrad when training.
- Add human engineered input features.
7. References
-
Alex Cates, Board game breakdown: Settlers of Catan, the basics, 2022. Link
-
Xavier Gastaldi, Shake-Shake regularization, 2017. arXiv:1705.07485
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Deep residual learning for image recognition, 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015), 770–778. arXiv:1512.03385
-
Jared Kaplan, Sam McCandlish, et al., Scaling laws for neural language models (2020). arXiv:2001.08361
-
Diederik Kingma and Jimmy Ba, Adam: A method for stochastic optimization, CoRR (2014). arXiv:1412.6980
-
Ilya Loshchilov and Frank Hutter, Decoupled weight decay regularization, International Conference on Learning Representations (2017). arXiv:1711.05101
-
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller, Playing Atari with deep reinforcement learning (2013). arXiv:1312.5602
-
Arthur Samuel, Some studies in machine learning using the game of checkers, IBM Journal 3 (1959), no. 3.
-
David Silver, Aja Huang, et al., Mastering the game of Go with deep neural networks and tree search, Nature 529 (2016), 484–489. Link
-
Samuel Smith, Pieter-Jan Kindermans, and Quoc Le, Don’t decay the learning rate, increase the batch size (2017). arXiv:1711.00489
-
Richard Sutton, Learning to predict by the methods of temporal differences, Machine learning 3 (1988).
-
Gerald Tesauro, Temporal difference learning and TD-gammon, Communications of the ACM 38 (1995), no. 3.